
V2 Multi-Datacenter Replication Reference: Architecture
v2 Multi-Datacenter Replication is deprecated and will be removed in a future version. Please use v3 instead.
This document provides a basic overview of the architecture undergirding Riak’s Multi-Datacenter Replication capabilities.
How Replication Works
When Multi-Datacenter Replication is implemented, one Riak cluster acts as a primary cluster. The primary cluster handles replication requests from one or more secondary clusters (generally located in datacenters in other regions or countries). If the datacenter with the primary cluster goes down, a secondary cluster can take over as the primary cluster. In this sense, Riak’s multi-datacenter capabilities are masterless.
Multi-Datacenter Replication has two primary modes of operation: fullsync and realtime. In fullsync mode, a complete synchronization occurs between primary and secondary cluster(s); in realtime mode, continual, incremental synchronization occurs, i.e. replication is triggered by new updates.
Fullsync is performed upon initial connection of a secondary cluster, and then periodically thereafter (every 360 minutes is the default, but this can be modified). Fullsync is also triggered if the TCP connection between primary and secondary cluster is severed and then recovered.
Both fullsync and realtime mode are described in detail below. But first, a few key concepts.
Concepts
Listener Nodes
Listeners, also called servers, are Riak nodes in the primary cluster that listen on an external IP address for replication requests. Any node in a Riak cluster can participate as a listener. Adding more nodes will increase the fault tolerance of the replication process in the event of individual node failures. If a listener node goes down, another node can take its place.
Site Nodes
Site nodes, also called clients, are Riak nodes on a secondary cluster that connect to listener nodes and send replication initiation requests. Site nodes are paired with a listener node when started.
Leadership
Only one node in each cluster will serve as the lead site (client) or listener (server) node. Riak replication uses a leadership-election protocol to determine which node in the cluster will participate in replication. If a site connects to a node in the primary cluster that is not the leader, it will be redirected to the listener node that is currently the leader.
Fullsync Replication
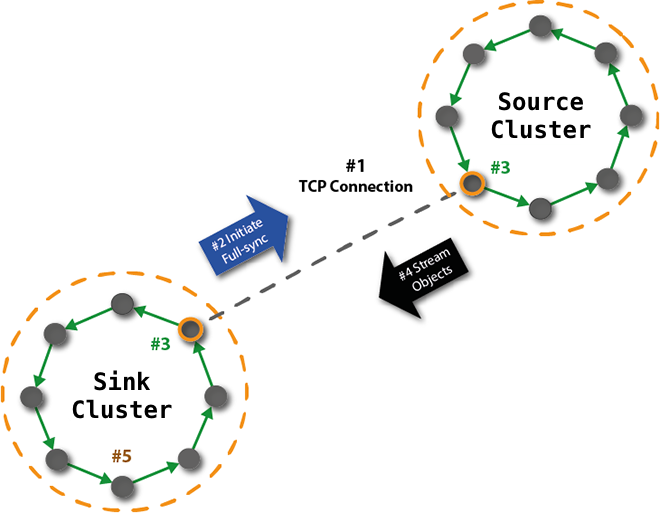
Riak performs the following steps during fullsync replication, as illustrated in the Figure below.
- A TCP connection is established between the primary and secondary clusters
- The site node in the secondary cluster initiates fullsync replication with the primary node by sending a message to the listener node in the primary cluster
- The site and listener nodes iterate through each vnode in their respective clusters and compute a hash for each key’s object value. The site node on the secondary cluster sends its complete list of key/hash pairs to the listener node in the primary cluster. The listener node then sequentially compares its key/hash pairs with the primary cluster’s pairs, identifying any missing objects or updates needed in the secondary cluster.
- The listener node streams the missing objects/updates to the secondary cluster.
- The secondary cluster replicates the updates within the cluster to achieve the new object values, completing the fullsync cycle
Realtime Replication
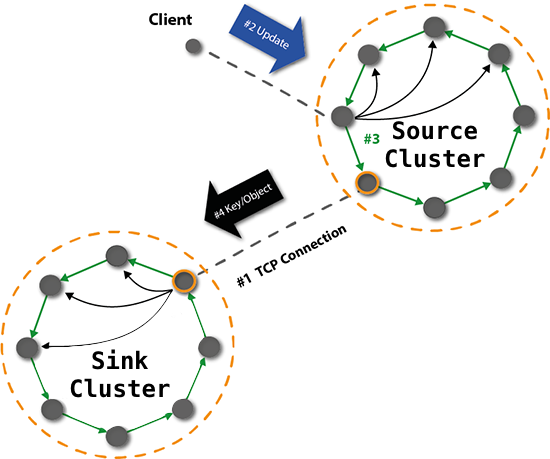
Riak performs the following steps during realtime replication, as illustrated in the Figure below.
- The secondary cluster establishes a TCP connection to the primary
- Realtime replication of a key/object is initiated when an update is sent from a client to the primary cluster
- The primary cluster replicates the object locally
- The listener node on the primary cluster streams an update to the secondary cluster
- The site node within the secondary cluster receives and replicates the update
Restrictions
It is important to note that both clusters must have certain attributes
in common for Multi-Datacenter Replication to work. If you are using
either fullsync or realtime replication, both clusters must have the
same ring size; if you are using fullsync
replication, every bucket’s n_val must be the same in both the
source and sink cluster.