
Using MapReduce
In Riak KV, MapReduce is the primary method for non-primary-key-based querying. Although useful for tasks such as batch processing jobs, MapReduce operations can be very computationally expensive to the extent that they can degrade performance in production clusters operating under load. Thus, we recommend running MapReduce operations in a controlled, rate-limited fashion and never for realtime querying purposes.
MapReduce (M/R) is a technique for dividing data processing work across a distributed system. It takes advantage of the parallel processing power of distributed systems and also reduces network bandwidth, as the algorithm is passed around to where the data lives rather than transferring a potentially huge dataset to a client algorithm.
You can use MapReduce for things like: filtering documents by tags, counting words in documents, and extracting links to related data. In Riak KV, MapReduce is one method for querying that is not strictly based on key querying, alongside secondary indexes. MapReduce jobs can be submitted through the HTTP API or the Protocol Buffers API, although we strongly recommend using the Protocol Buffers API for performance reasons.
Features
- Map phases execute in parallel with data locality.
- Reduce phases execute in parallel on the node where the job was submitted.
- MapReduce queries written in Erlang.
When to Use MapReduce
- When you know the set of objects over which you want to MapReduce (i.e. the locations of the objects, as specified by bucket type, bucket, and key)
- When you want to return actual objects or pieces of objects and not just the keys.
- When you need the utmost flexibility in querying your data. MapReduce gives you full access to your object and lets you pick it apart any way you want.
When Not to Use MapReduce
- When you want to query data over an entire bucket. MapReduce uses a list of keys, which can place a lot of demand on the cluster.
- When you want latency to be as predictable as possible.
How it Works
The MapReduce framework helps developers divide a query into steps, divide the dataset into chunks, and then run those step/chunk pairs in separate physical hosts.
There are two steps in a MapReduce query:
- Map - The data collection phase, which breaks up large chunks of work into smaller ones and then takes action on each chunk. Map phases consist of a function and a list of objects on which the map operation will operate.
- Reduce - The data collation or processing phase, which combines the results from the map step into a single output. The reduce phase is optional.
Riak KV MapReduce queries have two components:
- A list of inputs
- A list of phases
The elements of the input list are object locations as specified by bucket type, bucket, and key. The elements of the phases list are chunks of information related to a map, a reduce, or a link function.
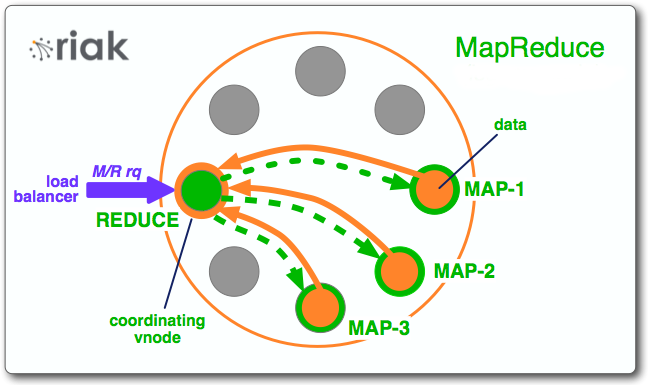
A MapReduce query begins when a client makes the request to Riak KV. The node that the client contacts to make the request becomes the coordinating node responsible for the MapReduce job. As described above, each job consists of a list of phases, where each phase is either a map or a reduce phase. The coordinating node uses the list of phases to route the object keys and the function that will operate over the objects stored in those keys and instruct the proper vnode to run that function over the right objects.
After running the map function, the results are sent back to the coordinating node. This node then concatenates the list and passes that information over to a reduce phase on the same coordinating node, assuming that the next phase in the list is a reduce phase.
The diagram below provides an illustration of how a coordinating vnode orchestrates a MapReduce job.
Example
In this example, we’ll create four objects with the text “caremad”
repeated a varying number of times and store those objects in the bucket
training (which does not bear a bucket type).
An Erlang MapReduce function will be used to count the occurrences of
the word “caremad.”
Data object input commands
For the sake of simplicity, we’ll use curl in conjunction with Riak KV’s HTTP API to store the objects:
curl -XPUT http://localhost:8098/buckets/training/keys/foo \
-H 'Content-Type: text/plain' \
-d 'caremad data goes here'
curl -XPUT http://localhost:8098/buckets/training/keys/bar \
-H 'Content-Type: text/plain' \
-d 'caremad caremad caremad caremad'
curl -XPUT http://localhost:8098/buckets/training/keys/baz \
-H 'Content-Type: text/plain' \
-d 'nothing to see here'
curl -XPUT http://localhost:8098/buckets/training/keys/bam \
-H 'Content-Type: text/plain' \
-d 'caremad caremad caremad'
MapReduce invocation
To invoke a MapReduce function from a compiled Erlang program requires that the function be compiled and distributed to all nodes.
For interactive use, however, it’s not necessary to do so; instead, we can invoke the client library from the Erlang shell and define functions to send to Riak KV on the fly.
First we defined the map function, which specifies that we want to get
the key for each object in the bucket training that contains the text
caremad.
We’re going to generalize and optimize it a bit by supplying a compiled regular expression when we invoke MapReduce; our function will expect that as the third argument.
ReFun = fun(O, _, Re) -> case re:run(riak_object:get_value(O), Re, [global]) of
{match, Matches} -> [{riak_object:key(O), length(Matches)}];
nomatch -> [{riak_object:key(O), 0}]
end end.
Next, to call ReFun on all keys in the training bucket, we can do
the following in the Erlang shell.
Do not use this in a production
environment; listing all keys to identify those in the training bucket
is a very expensive process.
{ok, Re} = re:compile("caremad").
That will return output along the following lines, verifying that compilation has completed:
{ok,{re_pattern,0,0,
<<69,82,67,80,69,0,0,0,0,0,0,0,6,0,0,0,0,0,0,0,99,0,100,
...>>}}
Then, we can create a socket link to our cluster:
{ok, Riak} = riakc_pb_socket:start_link("127.0.0.1", 8087).
%% This should return a process ID:
%% {ok,<0.34.0>}
Then we can run the compiled MapReduce job on the training bucket:
riakc_pb_socket:mapred_bucket(Riak, <<"training">>,
[{map, {qfun, ReFun}, Re, true}]).
If your bucket is part of a bucket type, you would use the following:
B = {<<"my_bucket_type">>, <<"training">>},
Args = [{map, {qfun, ReFun}, Re, true}]),
riakc_pb_socket:mapred_bucket(Riak, B, Args).
That will return a list of tuples. The first element in each tuple is the key for each object in the bucket, while the second element displays the number of instances of the word “caremad” in the object:
{ok,[{0,
[{<<"foo">>,1},{<<"bam">>,3},{<<"baz">>,0},{<<"bar">>,4}]}]}
Recap
In this tutorial, we ran an Erlang MapReduce function against a total of
four object in the training bucket. This job took each key/value
object in the bucket and searched the text for the word “caremad,”
counting the number of instances of the word.
Advanced MapReduce Queries
For more detailed information on MapReduce queries in Riak KV, we recommend checking out our Advanced MapReduce guide.